Request Tags to Property Bags: Migration Strategy
Overview
Migration from request_tags (lists of strings with no semantic model) to structured instrumentation using both context properties and property_bags (key-value pairs) for document processing application. The key benefits: property bags enable efficient storage, allow search/pivot operations on distinct dimensions, and provide a semantic model with optional standard dimensions that the product UI can understand and leverage.
Pay-i Dimension Context
For context, Pay-i organizes all dimensions into three categories:
Auto-collected dimensions (no migration needed):
model,model_version,tokens- Automatically captured from LLM callscost- Automatically calculated by Pay-i
Optional Standard Dimensions:
- Context properties (request-level):
use_case_step- Workflow phase ("extraction", "analysis") - Property bag dimensions (workflow-level, temporary):
account_name- Account context (transforms tosystem.account_name)
Custom Dimensions (customer-defined):
- Workflow-level (via use_case_properties):
document_id,batch_id- Business entities - Request-level (via request_properties):
llm_api_key- Operational metadata
Migration Benefits
Structured Analytics
- API Key Tracking: See which API keys process each document
- Step Analysis: Analyze costs by workflow step (extraction vs analysis)
- Batch Visibility: Group processing by batch_id
- Document Insights: Better filtering and correlation by document ID
Semantic Integration
- Product UI Awareness: Standard dimensions integrate with Pay-i dashboards and filtering
- Key-Value Structure: Efficient storage and querying compared to string lists
- Clear Separation: Explicit distinction between business context and operational metadata
Migration Decision Tree
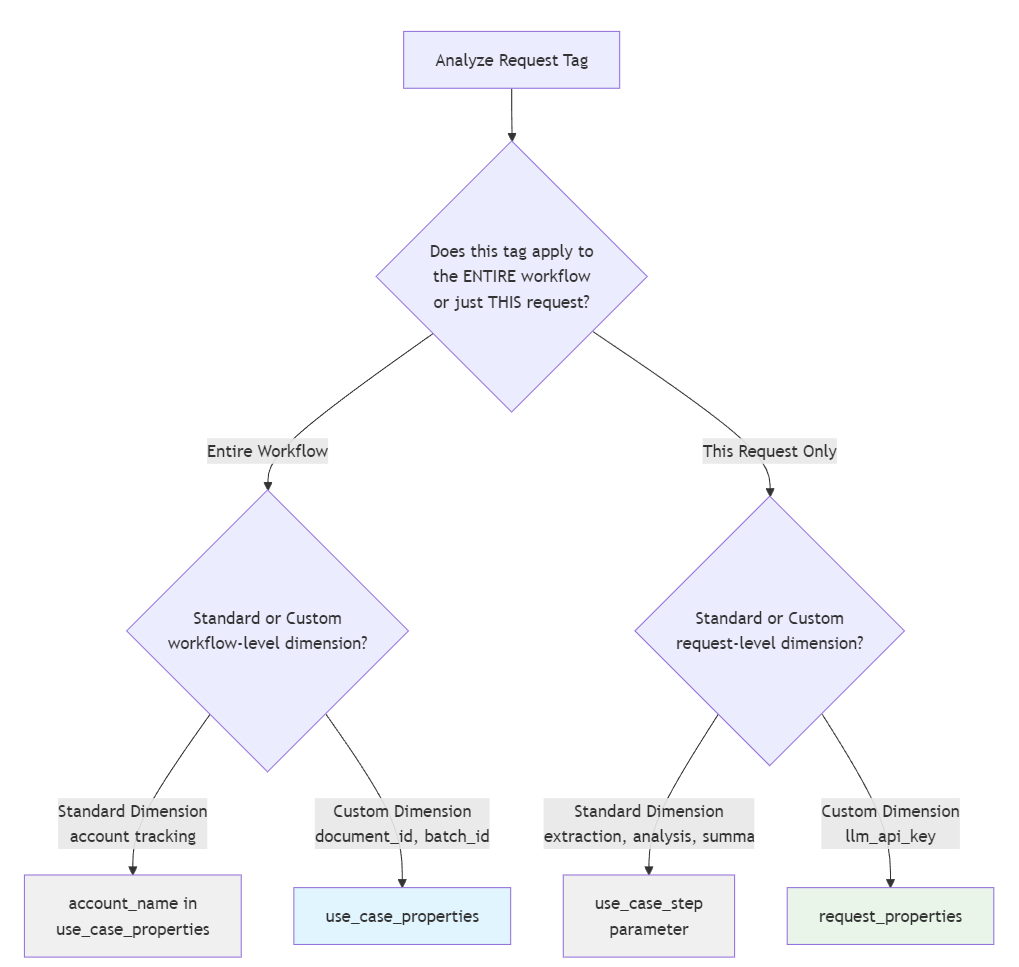
Migration Decision Process:
Workflow-Level Dimensions (use case instance):
- Standard Dimensions:
account_name→ specify inuse_case_properties - Custom Dimensions:
document_id,batch_id→ migrate touse_case_properties
Request-Level Dimensions (per request/call):
- Standard Dimensions:
extraction,analysis→ specifyuse_case_stepparameter - Custom Dimensions:
llm_api_key→ migrate torequest_properties
Document Processing Architecture
Recommended Pattern: Each use case instance processes one document through multiple steps, with batch_id grouping multiple documents.
# Document Processing Pattern
# Each use case = one document through extraction → analysis → summary
with track_context(
use_case_properties={
"document_id": "doc_123", # This document (spans entire workflow)
"batch_id": "batch_789", # Groups multiple documents
"account_name": get_account_name() # Account identification (→ system.account_name)
}
):
with track_context(
use_case_step="extraction",
request_properties={"llm_api_key": get_extraction_api_key()} # API key for extraction
):
extract_data() # Step 1 (model tracked automatically by Pay-i)
with track_context(
use_case_step="analysis",
request_properties={"llm_api_key": get_analysis_api_key()} # Different API key for analysis
):
analyze_data() # Step 2 (model tracked automatically by Pay-i)
with track_context(
use_case_step="summary",
request_properties={"llm_api_key": get_summary_api_key()} # Different API key for summary
):
summarize_data() # Step 3 (model tracked automatically by Pay-i)Key Questions for Migration
Scope Question: Does this metadata apply to the entire workflow or just this specific request?
Examples by Scope:
- Entire Workflow: document_id (when processing one document through multiple steps), batch_id
- This Request Only: llm_api_key
Standard vs Custom Dimensions
Auto-Collected Standard Dimensions (Automatic):
model,cost,tokens→ Automatically tracked by Pay-i
Optional Standard Dimensions (Must be specified):
use_case_step→ Context property:track_context(use_case_step="extraction")(intended method)user_id→ Context property:track_context(user_id="user123")(intended method)account_name→ Use case property only:use_case_properties={"account_name": get_account_name()}(no context property)
Custom Dimensions (Migrated from request_tags to property_bags):
document_id→ use_case_properties (custom business entity)batch_id→ use_case_properties (custom grouping identifier)llm_api_key→ request_properties (custom operational metadata)
Migration Focus: Standard dimensions have different SDK interfaces:
- Context properties:
use_case_stepanduser_idare available astrack_context()parameters AND inget_context() - Use case property only:
account_nameis NOT available as a context property, only via use case properties - Custom dimensions:
document_id,batch_id,llm_api_keyrequire property bags
Backend automatically adds system. prefix to all system properties.
Product Impact: When viewing data in Pay-i dashboards, exports, or APIs, these appear as:
- SDK:
track_context(use_case_step="extraction")→ Analytics:system.use_case_step: "extraction" - SDK:
{"account_name": "prod-account"}→ Analytics:system.account_name: "prod-account" - SDK:
track_context(user_id="user123")→ Analytics:system.user_id: "user123"
Customers will see the system.* field names in reporting and data exports, even though they specify values without the prefix in their code.
Batch Processing Architecture:
# Process multiple documents in a batch (multiple use case instances)
for document_id in batch_documents:
with track_context(
use_case_properties={
"document_id": document_id, # This document
"batch_id": "batch_789", # Batch grouping
"account_name": get_account_name() # Account identification
}
):
with track_context(use_case_step="extraction"):
extract_data(document_id)
with track_context(use_case_step="analysis"):
analyze_data(document_id)
with track_context(use_case_step="summary"):
summarize_data(document_id)Migration Patterns
Pattern 1: Single Document Processing
Before:
with track_context(request_tags=["document_123", "api_key_xyz"]):
response = client.chat.completions.create(...)After:
with track_context(
use_case_properties={
"document_id": "document_123",
"account_name": get_account_name()
},
request_properties={"llm_api_key": "api_key_xyz"}
):
response = client.chat.completions.create(...)Pattern 2: Multi-Step Document Workflow
Before:
with track_context(request_tags=["document_456", "extraction", "api_key_abc"]):
extraction = client.chat.completions.create(...)
with track_context(request_tags=["document_456", "analysis", "api_key_def"]):
analysis = client.chat.completions.create(...)After:
# One use case instance = one document through multiple steps
with track_context(
use_case_properties={
"document_id": "document_456",
"batch_id": "batch_789", # Groups multiple documents
"account_name": get_account_name() # Account identification
}
):
with track_context(
use_case_step="extraction", # Direct parameter
request_properties={"llm_api_key": get_extraction_api_key()} # Custom property
):
extraction = client.chat.completions.create(...)
with track_context(
use_case_step="analysis", # Direct parameter
request_properties={"llm_api_key": get_analysis_api_key()} # Custom property
):
analysis = client.chat.completions.create(...)Pattern 3: Batch Processing
Before:
# Processing multiple documents with repeated tags
for doc_id in ["doc_001", "doc_002", "doc_003"]:
with track_context(request_tags=["batch_789", doc_id, "extraction"]):
extract_document(doc_id)
with track_context(request_tags=["batch_789", doc_id, "analysis"]):
analyze_document(doc_id)After:
# Multiple use case instances grouped by batch_id
for doc_id in ["doc_001", "doc_002", "doc_003"]:
with track_context(
use_case_properties={
"document_id": doc_id,
"batch_id": "batch_789",
"account_name": get_account_name()
}
):
with track_context(use_case_step="extraction"): # Direct parameter
extract_document(doc_id)
with track_context(use_case_step="analysis"): # Direct parameter
analyze_document(doc_id)Implementation Approach
- Identify Request Tags: List all current request_tags usage
- Apply Decision Tree: Use the decision tree to categorize each tag
- Implement Gradually: Migrate one workflow at a time
- Test Inheritance: Verify property inheritance works as expected
- Validate Analytics: Confirm improved dashboard filtering and insights
Migration Mapping
| Current request_tag | Property Bag Type | New Location | Reason |
|---|---|---|---|
| document_id | use_case_properties | {"document_id": value} | Business entity |
| batch_id | use_case_properties | {"batch_id": value} | Business context |
| account_name | use_case_properties | {"account_name": get_account_name()} | Account ID (→ system.account_name) |
| extraction, analysis | use_case_step (context property) | use_case_step="extraction" | Workflow step parameter |
| api_key_xyz | request_properties | {"llm_api_key": value} | Request-specific |
Key Migration Considerations
Migration Requirements
This is a mandatory migration with no backward compatibility:
- The Enterprise SKU silently drops request_tags (they will not be captured)
- All request_tags must be migrated to property bags
- Migration must be completed before upgrading to the new stack
This focused approach provides the semantic power of property bags while maintaining the simplicity needed for single-developer implementation.
Updated 14 days ago